Humans Outperform AI in Complex Tasks: MIT Study Highlights AI's Planning and Change Detection Struggles
November 2, 2025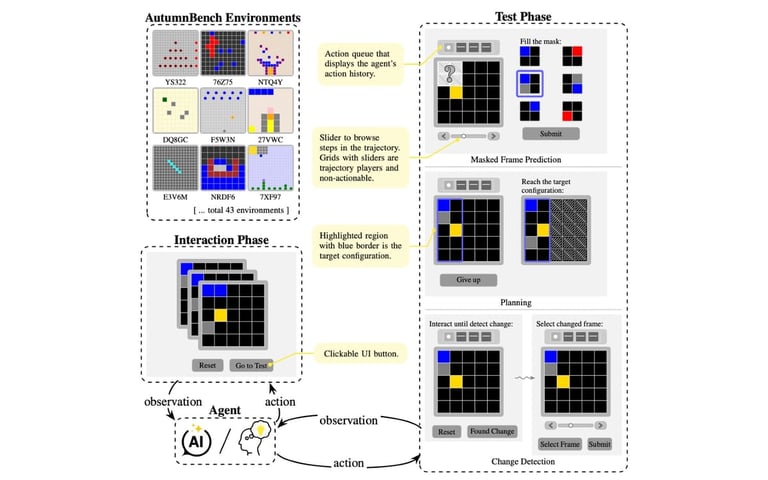
Weaker AI performance in 43 environments across 129 tasks shows humans consistently outpacing all three frontier models on masked-frame prediction, planning, and change detection, with AI struggles especially in change detection and planning.
The study was a MIT-led collaboration, with AutumnBench headed by Archana Warrier and infrastructure by Dat Nguyen, recruiting English-speaking participants via Prolific and secured with rigorous attention checks, funded by the Simons Foundation and partner institutions.
WorldTest’s design separates exploration from test phases, using derived challenges in modified environments to assess generalization of world-model learning beyond simple next-frame prediction.
The paper was submitted to arXiv in late October 2025, with public dissemination of findings following a few days later; a related coding-limits benchmark was noted earlier in June 2025.
The MIT-led effort tested 517 humans against three frontier models—Claude 4 Sonnet, OpenAI o3, and Google Gemini 2.5 Pro—using AutumnBench within WorldTest to probe how AI agents learn and model interactive environments.
AutumnBench features grid-worlds from 3×3 up to 25×25, averaging 16×16, with diverse object types and colors, and includes 19 of 43 environments containing stochastic elements; tasks target predicting hidden observations, planning action sequences, and detecting rule changes.
Increasing compute helped only a subset of environments (about 25 of 43 for some models) and did not close fundamental gaps in reasoning; updates to masking and change detection benefited less from more compute.
These results challenge AI emphasis on next-frame prediction and reward maximization, underscoring the need for metacognitive abilities, strategic experiment design, uncertainty quantification, and flexible belief updating for human-like environment understanding.
Model-specific takeaways include Claude 4 Sonnet’s heavy reliance on direct actions with limited resets/no-ops and weak change detection, OpenAI o3 showing variable but sometimes strong planning in certain settings, and Gemini 2.5 Pro displaying inconsistent performance with sparse change detection and frequent planning failures.
Humans demonstrated more deterministic, strategic exploration with higher use of resets and no-ops, and lower normalized perplexity, while AI models leaned more on pattern-matching, especially in stochastic environments.
Summary based on 1 source
Get a daily email with more AI stories
Source

PPC Land • Nov 2, 2025
MIT researchers expose major gaps in AI world understanding