Skywork Unveils Next-Gen Reward Models, Revolutionizing AI Alignment with Human Values
July 4, 2025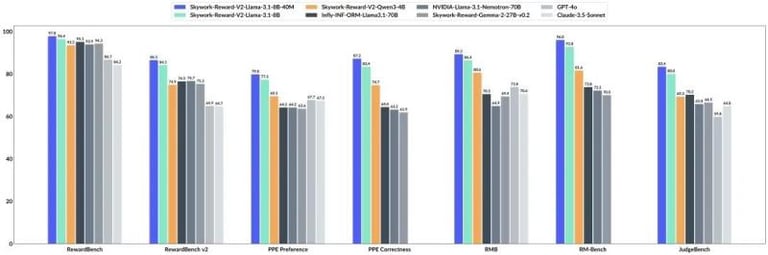
On July 4, 2025, Skywork unveiled Skywork-Reward-V2, the second generation of its open-source reward models, building on the success of the original series released in September 2024.
These new models are based on a range of underlying architectures, with parameters varying from 600 million to 8 billion, and they have achieved top rankings across seven major reward model evaluation benchmarks.
Skywork-Reward-V2 models excel in human preference alignment, objective correctness, safety, and resistance to style bias, making them versatile for various tasks.
To enhance model training and evaluation, Skywork developed a hybrid dataset named Skywork-SynPref-40M, which consists of 40 million preference pairs and emphasizes collaboration between human annotators and Large Language Models (LLMs).
The development process utilized a two-stage human-machine collaborative approach for data screening, significantly improving the quality and volume of the training dataset.
This innovative approach addresses common challenges faced by existing reward models, such as overfitting and the inadequate handling of complex human preferences.
Skywork's ongoing research aims to further enhance open-source reward models and explore new training techniques, positioning them as a critical component in future AI infrastructures.
The Skywork-Reward-V2 models are set to play a crucial role in guiding intelligent systems to align with human values and complex decision-making scenarios.
Since their initial release, these models have garnered over 750,000 downloads on the HuggingFace platform, indicating significant adoption within the open-source community.
The release of these models marks a significant milestone in the evolution of open-source reward systems and aims to advance research in Reinforcement Learning from Human Feedback (RLHF).
Overall, the Skywork-Reward-V2 models lay the groundwork for future AI infrastructure that closely aligns with human values.
Summary based on 4 sources
Get a daily email with more AI stories
Sources

Skywork AI • Jul 4, 2025
Skywork-Reward-V2: Leading the New Milestone for Open-Source Reward Models
The Manila Times • Jul 4, 2025
Skywork-Reward-V2: Leading the New Milestone for Open-Source Reward Models
LianPR • Jul 4, 2025
Skywork-Reward-V2: Leading the New Milestone for Open-Source Reward Models