NVIDIA's ALCHEMI Toolkit Boosts Simulation Speeds by Up to 33x with GPU Acceleration
April 14, 2026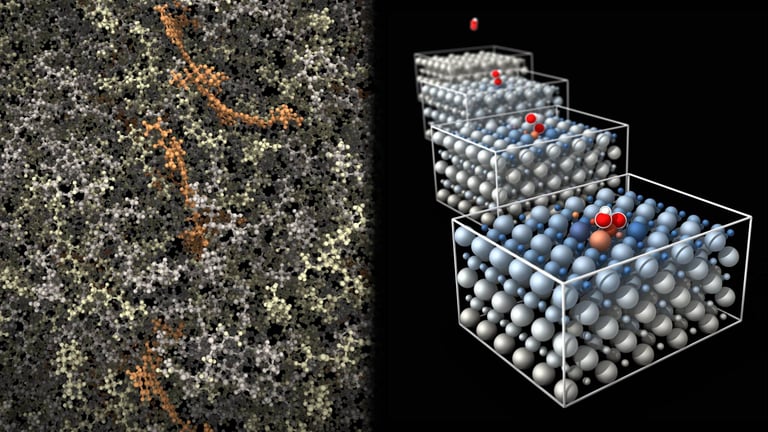
Data management keeps simulation data resident on the GPU to avoid transfers, using AtomicData and Batch objects, with native ASE and Pymatgen interfaces and Zarr-based storage for efficient batch writing.
Key integration partners include Orbital (OrbMolv2 with PME electrostatics and MTK integrator), MATGL (TensorNet integration for faster property predictions), and Matlantis leveraging Toolkit-Ops for high-throughput workloads.
The toolkit sits between domain-specific GPU kernels and deep learning models, enabling composable simulation workflows with features like geometry relaxation, molecular dynamics, and multi-stage pipelines.
It supports building end-to-end workflows with customizable dynamics classes, model wrappers, and advanced data management to minimize CPU-GPU data transfers and maximize GPU residency for large-scale simulations.
Early adopters report meaningful performance gains, including roughly 1.7x acceleration for large systems and up to 33x speedups for batched smaller systems with GPU-accelerated graph construction.
System requirements include Python 3.11–3.13, PyTorch 2.8+, CUDA 12+, Linux or macOS, NVIDIA GPUs with compute capability 7.0+, at least 4 GB RAM (16 GB recommended), along with installation steps and links to the GitHub repository and documentation.
Two scaling approaches are offered: FusedStage for single-GPU deployment and a distributed multi-GPU pipeline, demonstrated with eight GPUs for geometry optimization and eight for Langevin dynamics.
The toolkit is available on GitHub at NVIDIA/nvalchemi-toolkit, with JAX support planned for version 0.2.0.
Core capabilities include batched dynamics kernels, JAX support, and integration with neighbor list construction, DFT-D3 dispersion, and long-range electrostatics via Toolkit-Ops.
The framework supports custom model integration with wrappers and built-in support for MACE, TensorNet, and AIMNet2 architectures.
NVIDIA ALCHEMI Toolkit provides a GPU-accelerated framework to build custom atomistic workflows, bridging MLIP models with physics-based calculations for quantum-like speed and accuracy.
Usage patterns demonstrated include combining FIRE2 optimizers with VelocityVerlet dynamics, both on single GPUs and distributed multi-GPU setups, with API-oriented code examples for assembling and running batched workflows.
Summary based on 2 sources
Get a daily email with more AI stories
Sources

NVIDIA Technical Blog • Apr 13, 2026
Building Custom Atomistic Simulation Workflows for Chemistry and Materials Science with NVIDIA ALCHEMI Toolkit
Blockchain.News • Apr 15, 2026
NVIDIA Launches ALCHEMI Toolkit for GPU-Accelerated Chemistry Simulations